“Open-Source & R @Pharma & CRO”
Was bedeuten die o.g. Anforderungen im Pharma Kontext?
- Vertrauenswürdigkeit der eingesetzten Software \(\rightarrow\) Validierung
- Nachvollziehbarkeit der Ergebnisse \(\rightarrow\) Good Software Engineering Practice
- Reproduzierbarkeit der Ergebnisse \(\rightarrow\) Alle Stakeholder müssen die R-Skripte selber neu durchlaufen lassen können und müssen die geichen Resultate erhalten
Vertrauenswürdigkeit der eingesetzten Software
- Die FDA hat ausgesagt, dass die eingesetzten R Pakete “reliable” sein müssen.
- Das kann durch eine klassische formale Validierung wie bei “rpact” gezeigt werden
- Oder durch einen nicht so formalen “Risik Assessment” Ansatz, wie er z.B. vom R Validation Hub (pharmar.org/risk) propagiert wird
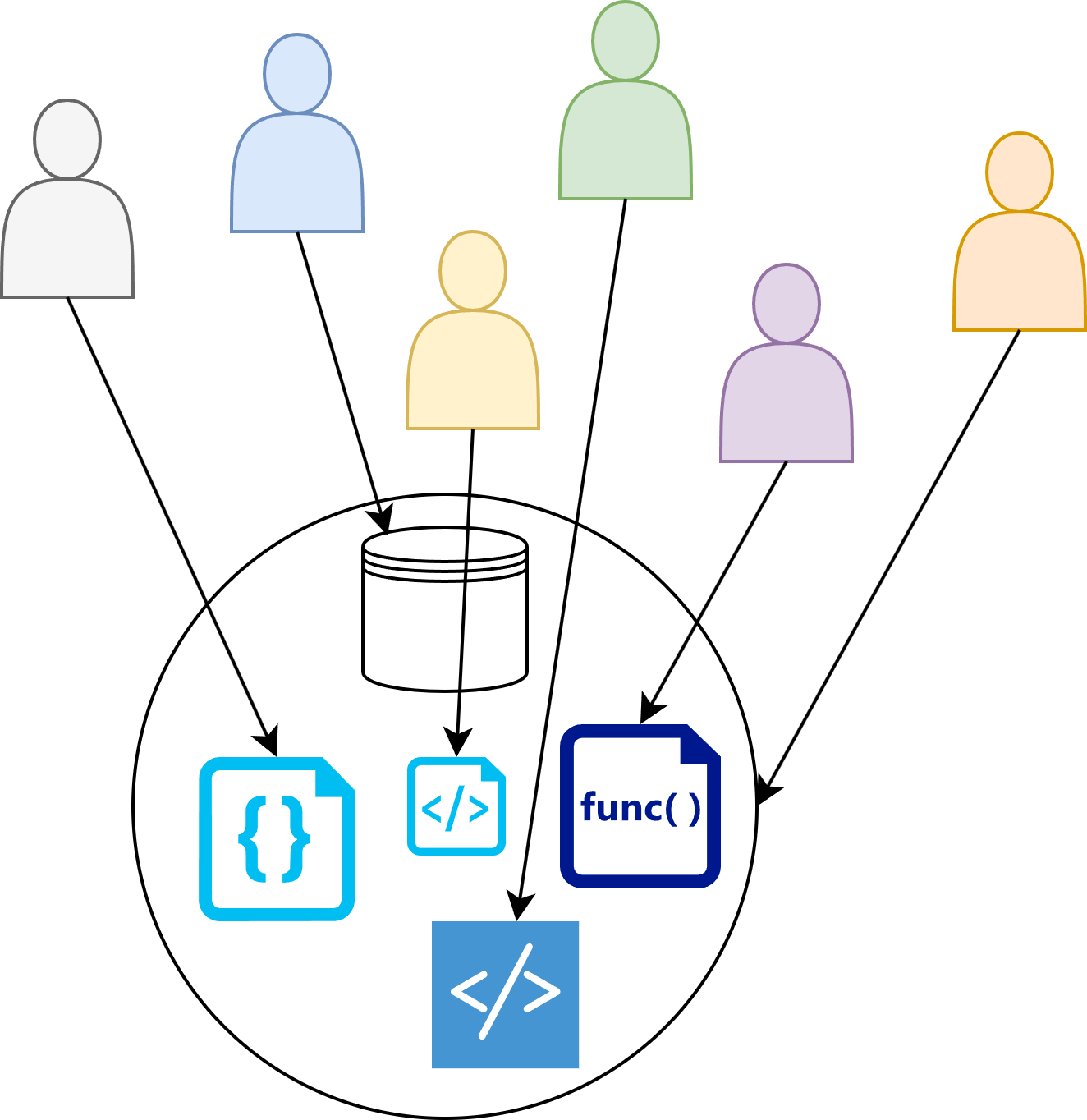
Nachvollziehbarkeit der Ergebnisse
- Statistische Programmierer müssen “Good Software Engineering Practices” anwenden
- Dazu gehört z.B. die Anwendung von “Clean Code Rules”:
- Wartbarkeit: Der Code ist lesbar und verständlich und hat eine reduzierte Komplexität, d. h., es ist einfacher, Fehler zu beheben.
- Erweiterbarkeit: Die Architektur ist einfacher, sauberer und ausdrucksvoller, d. h., es ist einfacher, den Funktionsumfang zu erweitern und das Risiko von Fehlern zu reduzieren.
- Performance: Der Code läuft schneller, benötigt weniger Speicher oder ist einfacher zu optimieren.
Nachvollziehbarkeit der Ergebnisse
- “Good Software Engineering Practices” und “Clean Code Rules”…
- Spätestens an dieser Stelle wird klar, dass Statistiker immer mehr Knowhow aus den Computerwissenschaften benötigen
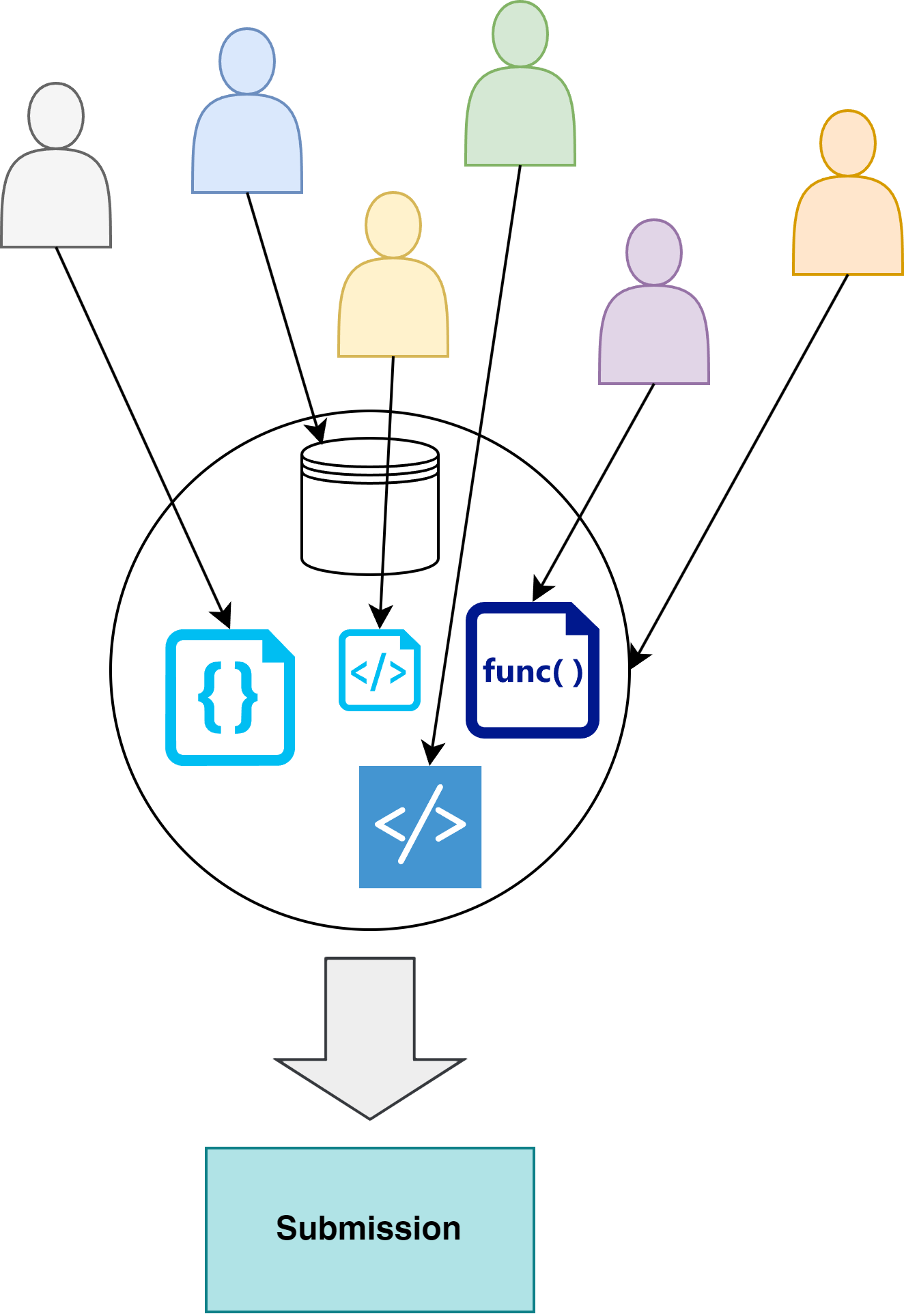
Reproduzierbarkeit
- Bisherige Lösungen zur Gewährleistung der Reproduzierbarkeit von R-Skripten erfordern oft komplexe Setup-Prozesse, die nur von Experten durchgeführt und gewartet werden können.
- Docker-Container sind ein bekanntes Beispiel. Sie beinhalten das gesamte Betriebssystem sowie alle benötigten Abhängigkeiten und Softwarekomponenten.
- Diese Ansätze sind jedoch schwerfällig und ressourcenintensiv, z.B. im Hinblick auf Manpower und Speicherplatz, was z.B. ihre Implementierung und Archivierung teuer macht und das Teilen erschwert.
- Leichtgewichtige Lösungsansätze?
- Eine effiziente Qualitätskontrolle des Projekt-spezifischen R-Codes wird mitgeliefert:
- Strenge CRAN-Package-Checks
- Automatisch generierte Unit Tests stellen sicher, dass Code-Änderungen keine unerwünschten Nebeneffekte haben
- Risiko-Metriken lassen sich automatisch prüfen
- Die Code-Dokumentation kann automatisch in ein Handbuch zum Code überführt werden
- Das Dependency-Management ist integriert, d.h. alle Abhängigkeiten sind sauber definiert (R Paket: renv)
- Das Code-Styling kann automatisch optimiert und vereinheitlicht werden, d.h. jeder kann weiterhin in seinem eigenen Stil programmieren
- Verfügbare Risk Assessment Tools können direkt benutzt werden
- Bei Nutzung des Tools ist eine steile Lernkurve zu erwarten, ohne die verschiedenen User mit ihren ganz individuellen Kenntnissen und Vorlieben zu verschrecken oder zu überfordern
- Leichtgewichtige Lösung, die die Herausforderung bei der Wurzel angeht und nicht nur Symptome bekämpft
Realisierung
- Ist das Interesse an einem gemeinsamen, Firmen-übergreifenden Projekt da?
- Wie könnten wir das realisieren?
- Das Erstellen guter Trainings ist sehr zeitaufwändig
- Ein neues R Paket, welches das Lernen guter Programmierpraxis im Bereich Pharma unterstützt und den Output vereinheitlicht sollte Bestandteil des Projekts sein, idealerweise mit RStudio Erweiterung (Addin basierend auf einer Shiny GUI)
Mögliche Projektphasen
- Sammlung spezifischer Bedarfe der am Projekt beteiligten Firmen
- Priorisierung von Trainingsmodulen
- Erstellung erster Trainingsmodule
- Implementierung eines Prototypen des integrierten Tools
- Pilot-Training in einer Firma unter Nutzung des integrierten Tools
- Systematische Feedbacks \(\rightarrow\) Optimierung der Module und des integrierten Tools
- Weitere Trainings in anderen Firmen
- Online-Stellen von Trainingsmodulen
- Veröffentlichung der 1. Version des Tools auf GitHub und CRAN
Wer könnte an der Realisierung aktiv mitarbeiten
- Daniel Sabanes Bove (RCONIS): Trainings und Integriertes Tool (R-Paket-Entwicklung)
- Friedrich Pahlke (RPACT, RCONIS): Trainings und Integriertes Tool (R-Paket/Shiny-App-Entwicklung)
- Lars Andersen (BI, RPACT): Trainings
- ???
Das Training “Good Software Engineering Practice for R”, initial entwickelt von Daniel, Kevin und Friedrich, ist bisher in Basel, Shanghai und San Francisco gelaufen (siehe openstatsware.org); dieses Jahr: UseR!-Konferenz, Salzburg (Daniel und Friedrich).